
Bias vs. Variância (Parte 3)
Depois de tanto tempo, a terceira parte da série Bias vs. Variância saiu!
Apenas relembrando, a série foi dividida da seguinte forma:
- Primeira parte: conceito de bias e variância
- Segunda parte: cálculo do bias e da variância
- Terceira parte: métodos de redução do bias e da variância
Em resumo, enquanto o bias está ligado à capacidade das predições do modelo se aproximarem dos valores reais, a variância está relacionada à consistência dos resultados do modelo em diferentes conjuntos de dados.
Apesar de sabermos calcular “explicitamente” o bias e a variância de um modelo, dependendo do tamanho do conjunto de dados (número de variáveis e samples) e da complexidade do modelo, o processo pode ser computacionalmente caro. Desta forma, precisamos ter outras maneiras de inferir se estamos com problemas de bias ou variância.

At Netflix, big data can affect even the littlest things
You weren’t alone. You fired up your Netflix (s nflx) device a couple Fridays ago, happened across Orange is the New Black in your Netflix recommendations, started watching the first episode and then wondered why you’d never heard of it. Netflix’s other original programming — House of Cards and Arrested Development — received huge preavailability marketing, and they weren’t even this good.
The answer to your question, like the answer to so many other questions these days, is data. Netflix didn’t have to spend millions of dollars advertising the new show hoping you would tune in — it knew you’d see it in the recommendations, it knew you’d give it a try and it knew you’d like it. According to the company during its earnings call on Monday, “Orange is the New Black” actually had more viewers watching more hours than during its first week than its predecessors had.
Ver o post original 873 mais palavras
Machine Learning: 12 importantes lições
O conhecimento que não é facilmente encontrado em livros e proveniente da experiência de pesquisadores/profissionais da área.
A Few Useful Things to Know about Machine Learning (pdf)
Artigo escrito por Pedro Domingos (2012), Professor do Departamento de Ciência da Computação e Engenharia na Universidade de Washington.
- Learning= Representation + Evaluation + Optimization
- It’s Generalization That Counts
- Data Alone Is Not Enough
- Overfitting Has Many Faces
- Intuition Fails In high dimensions
- Theoretical guarantees are not what they seem
- Feature Engineering Is The Key
- More Data Beats A Cleverer Algorithm
- Learn Many Models, Not Just One
- Simplicity Does Not Imply Accuracy
- Representable Does Not Imply Learnable
- Correlation Does Not Imply Causation
A practical intro to Data Science
Uma vasta lista de recursos – artigos, livros, cursos, etc – sobre as diferentes disciplinas importantes para quem está interessado em Data Science:
http://blog.zipfianacademy.com/post/46864003608/a-practical-intro-to-data-science
😉
Bias vs. Variância (Parte 2)
Recapitulando…
No primeiro post, mostramos a definição de bias e variância e como esses tipos de erro se relacionam com o ajuste do modelo aos dados. Abaixo segue um resumo mais visual: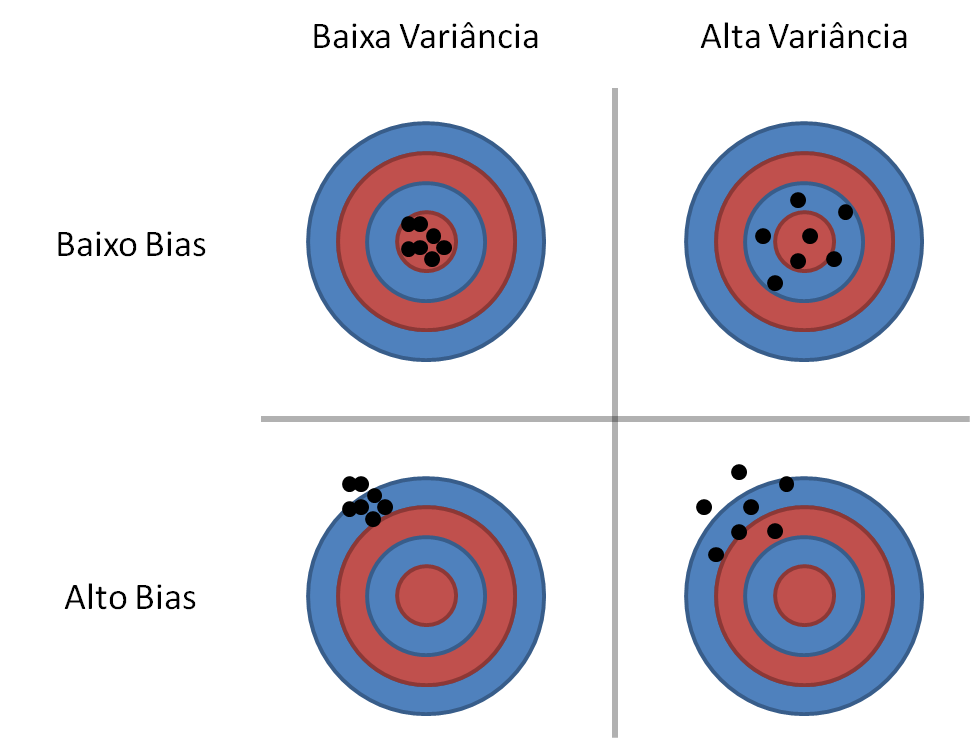
Lidando com variáveis categóricas – Python
Ao criarmos um modelo, é comum termos variáveis categóricas importantes para a explicação da nossa variável alvo. Entretanto, modelos são quantitativos e, portanto, precisam ter variáveis numéricas.
Para lidar com esta limitação, uma prática bastante comum é criar uma nova variável para cada possível valor assumido pela variável em questão – em circuitos digitais, esse processo é conhecido como One Hot Encoding. Por exemplo, se possuímos uma variável com domínio {“Quente”, “Morno”, “Frio”, “Gelado”}, podemos torná-la numérica utilizando 4 variáveis – também conhecidas como dummies – da seguinte maneira:
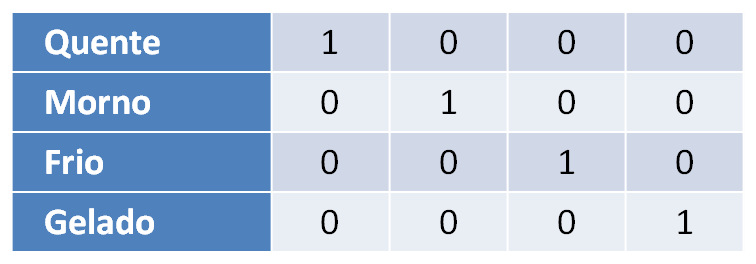
Desta maneira, você mapeará a influência de cada possível valor categórico em uma nova variável.
Mas o que fazer quando o número de categorias é muito grande?
Bias vs. Variância (Parte 1)
É comum, ao construirmos e escolhermos parâmetros para um modelo, nos depararmos com a seguinte questão: como reduzir o erro do modelo?
Para respondermos essa pergunta de maneira correta, em primeiro lugar, devemos entender os 2 principais componentes do erro em nossas predições: bias e variância. Conhecendo melhor esses tipos de erro, podemos entender as possíveis fontes de erro em nosso modelo e como minimizá-lo.
MapReduce – Python (Parte 2)
Em nosso último post, o objetivo foi mostrar que um processo MapReduce é composto de 3 fases:
- Map -> Para cada “registro” de entrada, aplicamos uma função definida.
- Agrupamento e ordenação -> A saída da primeira etapa é reunida em grupos, que são ordenados.
- Reduce -> Para cada grupo da etapa 2, aplicamos uma função definida.
Hoje, mostraremos em detalhes como é definida cada etapa e qual a participação de cada uma na resolução de um problema.
